The use of ``postage-stamp'' animations with ``fbanim'' can provide useful
visualization capabilities.
Unfortunately,
if there are enough frames to present a smooth sense of motion,
the individual images are so small that details are lost.
If the images are made larger, the motion is no longer smooth.
Videotape offers the ability to maintain
a moderate image size (usually at least 640x480 pixels) with a passable
time resolution (25-30 frames per second).
There are several things which must be determined when preparing
to make frames for videotape. These are:
- The frame rate of recording media.
- The capabilities of the video tape format.
- The appropriate image size and quality.
- The aspect ratio of the images.
- Color selection.
- Computational capacity.
- Storage capacity.
The television and video industry has not settled upon a world-wide standard
for the encoding of video pictures.
Some of the basic elements are common to all the standards
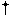 Each frame of video is comprised of two ``fields.''
A field consists of either the even numbered scanlines or the
odd numbered scanlines from the frame.
To display the frame,
first the field made up of the odd numbered scanlines is displayed.
When this is completed, the field containing the even numbered scanlines is
displayed.
Each frame of video is comprised of two ``fields.''
A field consists of either the even numbered scanlines or the
odd numbered scanlines from the frame.
To display the frame,
first the field made up of the odd numbered scanlines is displayed.
When this is completed, the field containing the even numbered scanlines is
displayed.
The NTSC video encoding system (used in the United States and Japan)
displays approximately 30 frames per second.
This means that 60 fields are displayed per second. The flicker that would
ordinarily be perceived at 30 frames per second is substantially reduced.
The PAL (Western Europe and Australia) and
SECAM (France & former Soviet Union variant) encoding formats
display 25 frames per second or 50 fields per second.
It is worth noting that
not all videotape formats are created equal.
Some are capable of retaining more image detail than others.
The table below lists the number of side-by-side alternating black-and-white
vertical lines
which can be discerned in 3/4 the width of a single frame of video
using
each of the video recording formats.
This is referred to as ``video lines of resolution'' or
``TV Lines'' in the video technology literature.
Resolution of
Video Recording Formats
===========================
Format VLines
---------------------------
VHS (1/2 inch) 240
3/4 inch 260
3/4 inch SP 380
SVHS (1/2 inch) 400
Hi8 400
BetaCam SP 400
D2 Digital Video 440
There are other differences between the various formats listed. The table
is roughly ordered from lowest to highest image quality.
If possible, avoid using formats closer to the top of the table for
making original recordings.
Choose the best format available to you for making original recordings.
It is usually easy to duplicate an original to a less capable
format for distribution.
Plan on making all duplicates from original recordings if possible.
Second and third generation copies made with the analog recording
formats will show degradation in color (bleeding and noise),
image stability (straight lines become wavy), and resolution.
If the distribution copies of your animation must be provided on
VHS, keep in mind that fine details in the scene may be lost when
the transfer is made to this format.
In order to know what size images need to be computed it is necessary to know
something about the hardware that will be used to convert the images to a
video signal.
The video encoding system found in the Silicon Graphics Iris (tm) family
of workstations encodes a 640x480 pixel image.
The Abekas A60 Digital Video Disk system encodes an image that
is 720x486 pixels in size.
Other video encoding hardware may use other resolutions.
You should determine the image size encoded by your hardware.
Frames should actually be computed at twice the resolution that will be used
for the encoding (e.g. 1280x960 instead of 640x480)
The ``pixhalve'' program is used
to reduce frames to the appropriate size for video encoding.
The filter kernel used by pixhalve reduces sampling artifacts
such as the pixel staircase effect on diagonal lines (a.k.a. ``jaggies'')
in the final image.
It also attempts to ``spread'' single pixel details slightly (such as specular
glints of light off surfaces).
This slight spreading helps to compensate for the fact that
current video encoding and recording techniques have difficulty with such
fine details.
The ``-J1'' option should also be given to rt.
This turns on the ``ray jittering'' feature of rt.
Ordinarily, rt traces rays through the center of each pixel. This can
lead to visual artifacts resulting from the regular sampling grid.
When ray jittering is enabled, rt picks a different location inside
each pixel at which it traces the ray. This reduces the regularity of the sampling grid, and hence any artifacts
that might result.
The rt program fits a viewing cube with 1:1 aspect ratio in model coordinates
to the dimensions of the image being created.
This means that whenever a non-square image is created (such as
a 4:3 aspect ratio picture for use in video recording) the image
is distorted.
This is most noticeable when computing images of involving circular objects
such the sphere, rcc (right circular cylinder) or the torus.
This becomes a problem when preparing images for visual analysis
and animation. The ``-V'' option to rt provides the solution to the problem.
The following shell script demonstrates the use of the this option.
#!/bin/sh
#
# compute 640x512 image to be displayed on system with square pixels.
# compensate for the distortion of the viewing cube.
#
rt -M -w640 -n512 -V640:512 -oimg.pix moss.g 'all.g' 2>> img.log << EOF
viewsize 1.421157820291206e+02;
eye_pt 20.21 -71.12 26.12;
orientation .707 0.0 0.0 .707;
start 0;
end;
EOF
This option should be used
whenever non square images are being prepared, or when the images will be
displayed on a system with pixels which do not have a 1:1 aspect ratio.
The option allows the user to compensate for the distortion introduced
in these situations. Note that in the example above, ``-V5:4'' would have
produced the same results.
Many users find that using the dimensions of the image being computed is
easier than computing the aspect ratio in small integers.
Video has a very limited capacity for color.
It also does not have equal capacity for storing the primary colors
red, green, and blue.
This usually comes as a great disappointment to people accustomed to
looking at computer images in rich detail on workstation monitors.
Whenever possible, the colors for objects in a video scene
should be chosen to match the abilities of the video system being used.
The first rule of thumb is: if an image or scene is going to be
recorded on video, the colors should be chosen by viewing the scene
through the video encoder,
not on the workstation monitor. A good approach is to
render several images from your animation sequence, and
record long runs of them in the same manner that will be used for the
final animation frames. View this test recording to see how colors will
appear in the final result.
Blue objects in a scene are most likely to have visual noise to their
appearance. A large smooth blue surface is likely to look ``grainy'' in the
final result. Small blue details will get lost in the noise.
Red objects are most likely to contribute to
smearing or color-bleeding in the final result.
Where possible, avoid placing bright or predominantly red objects
next to areas of important detail.
One other consideration worth mentioning is that no
color in the scene should have more than a 75 percent level of saturation.
While this is rarely a problem with images generated by rt, it is a frequent
``beginner's mistake'' when preparing title frames or other
hand-painted images.
The ``fbcolor'' program makes the viewing and selection of specific colors
easy.
It also reports the saturation level of the colors it displays as a
number from 0 to 255.
You should avoid using any color which fbcolor reports
as having a saturation over 191.
If you should notice that an object image created by rt lacks depth or
surface detail (such as a lighted cylinder which shows no shading along
the curved surface), check to see what color it was given in the model.
Reducing the saturation of the color given the object should help improve
its appearance.
There is a tradeoff to be made between the number of frames computed (and
hence the computational requirements) for a sequence of a given duration
and the quality of the motion in the result.
Larger numbers of frames (and more CPU time expended in their creation)
result in smoother motion. Fewer frames per second
result in more ``jerky'' movement of the camera and objects.
The smoothest motion is obtained when an image is computed for each field
of the final animation. Under NTSC this produces the appearance of 60
separate images per second. This is just above the threshold at which
most individuals perceive flicker.
The scanlines for each field must be extracted from
the images.
The two fields which form a video frame are combined together to create
the video frames using the pixfields program.
These are then encoded to video and recorded.
Besides the computational requirements, the only drawback is that
sequences created in this manner do not look as pleasing when used
with ``freeze frame'' features common on videotape machines.
The most common compromise is to compute one image for each video frame
of the final result. There is no requirement for field compositing, and
the image obtained from a ``freeze frame'' of the videotape machine is
pleasing. Under NTSC this produces the effect of 30 frames per second.
If each frame is shown for two or more successive frame times,
the perception of motion begins to suffer. For any
finished product it is advisable to use each image
for three or fewer frame-times.
It can take hours, days, or weeks of time for rt to create
all of the images in an animation sequence. As a result, there is a greater
probability that rt will be interrupted before it can finish the task.
If 200 images of a 300 image animation were completed before rt was
interrupted, it would be a waste to re-create those images when rt is
restarted.
Therefore rt was given some heuristics
to allow it to avoid duplicating results and wasting CPU time.
Whenever the rt program is asked to create an image, it first looks to see
if the image already exists. If the image file exists and is read-only,
the image is assumed to be completed and rt moves on to the next
image. If the image file exists and is writable, then rt looks for
black pixels (R,G,B color 0,0,0) in the image.
Since rt never creates image pixels with this exact
color, any such pixels it finds in the image are recomputed. If the file
is smaller than the final image should be, rt computes only
the missing portion
to complete the file.
The amount of time required to create the frames of a particular animation
sequence can be reduced by employing more than one machine to perform the
task. This can be done by giving multiple machines portions of the sequence
to create. If the sequence is divided up into frames, each machine can work
on a set of frames. Alternatively, the program ``remrt'' can be used in place
of the ``rt'' program. Remrt
distributes the computational load for each frame across a large number of
machines. Each machine is assigned a portion of the image to prepare.
The result is assembled on a single machine. For a more complete discussion
of remrt see [Muuss90a].
Animation frames can require a great deal of disk space. If the frames for a
20 second animation at 30 frames per second were computed at a resolution of
1440x972 pixels per image,
the result would be approximately 2.4 gigabytes of storage.
Fortunately, it is possible to reduce this requirement substantially.
The rt program can be given a shell command to execute from
within the animation script.
For example, the file ``ell.proto'' could have looked like this:
viewsize @0;
eye_pt @1 @2 @3;
orientation @4 @5 @6 @7;
start @(line);
clean;
anim all.g/ellipse.r matrix rmul
1 0 0 @8
0 1 0 @9
0 0 1 @10
0 0 0 1;
end;
! framedone.sh ell.pix @(line);
After each image is completed, rt would execute the shell command
``framedone.sh'' with the image number for an argument.
This shell script can be used to run pixhalve and compress the results and
perform other functions. For example:
% cat framedone.sh
#!/bin/sh
# Script to be run by rt whenever a frame of an animation is completed.
# Should be invoked from rt animation script as follows:
#
# viewsize 200;
# eye_pt 20. 0.0 83.25;
# orientation 0.0 0.0 .9238 .3826;
# start 3;
# end;
# ! framedone.sh file.pix 3;
#
if [ $# -ne "2" ] ; then
echo "Usage: $0 basename.pix frame_number" ; exit
fi
echo $0 $*
if [ "$2" -eq "0" ] ; then
FILE=$1
else
FILE=$1.$2
fi
pixhalve -w1440 $FILE > $FILE.sm
chmod -w $FILE.sm
compress $FILE.sm
chmod +w $FILE
mv $FILE.sm.Z $FILE
The second ``if'' statment in this script is necessary because rt does not
append a frame number to the filename of the first image in an animation
sequence.
This preserves compatibility with scripts intended for creating a single
frame.